
来源:香港經濟導報 2025年02月10日 版次:P62
文 ︱ 本刊首席記者 納婕謐
1月20日,“反中”第一人特朗普正式二次入主白宮,就職美國第47任總統。沒有任何意外的話,這一天應該可以說是美國“抗中派”們的高光時刻,頭版頭條也應該都是關於特朗普將如何刀俎中國的敘事,可意外偏偏發生了。
就在特朗普登臺同日,中國發佈人工智能(AI)大型語言模型DeepSeek-R1,這一模型立刻引發了美國廣泛關注,一時間,“中國的AI是超過美國了嗎?”成了兩國人民最為關心的問題。
有人說,中美AI競賽的“斯普特尼克(Sputnik)時刻”到來了,即蘇聯於1957年首度發射的人造衛星、被視為掀起太空競賽的歷史一刻。
看前小科普
人工智能(英語:artificial intelligence,縮寫為AI):人工智能可以定義為模仿人類與人類思維相關的認知功能的機器或電腦,如學習和解決問題。人工智能是電腦科學的一個分支,它感知其環境並採取行動,最大限度地提高其成功機會。此外,人工智能能夠從過去的經驗中學習,做出合理的決策,並快速回應。
大語言模型:是一種利用機器學習技術來理解和生成人類語言的人工智能模型。能夠執行文本分析、情緒分析、語言翻譯和語音識別等任務。
算力、算法与数据与AI的关系:数据是AI学习的“营养”,算力是执行算法、处理数据的“肌肉”,而算法则是指导机器学习的“大脑”。
DeepSeek創始人:中國AI不可能永遠是跟隨者
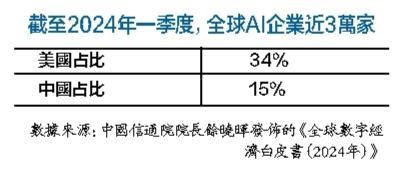
2023年,美國科技公司OpenAI發佈重磅語言模型GPT-4,自此開啟人類的AI元年,這一年,美國在AI領域顯現出的開創性和領先性令中國望其項背,也令中國焦慮不已,因為AI正代表著人類的下一場“工業革命”,輸了的後果不可想像。
但或許正是因為看到兩國間巨大的技術差距,除了騰訊、百度等有雄厚資金的巨頭公司選擇動用上億資金進行底層通用大模型的研究,其他中國公司大多選擇利用美國開發和開放的現成模型架構進行應用創造,快速營造利潤,收穫經濟上的回報。
美國發明什麼,中國便拿來進行加工,最終製造為產品獲利,這個劇本聽起來非常熟悉,對於中國的聰明才智者們來說,這條致富之路也更為輕鬆。但一位來自廣東湛江、畢業於浙江大學的年輕人選擇對這種成功路徑說了“不”。
他認為“過去很多年,中國公司習慣了別人做技術創新,我們拿過來做應用變現,但這並非是一種理所當然。這一波浪潮裏,我們的出發點,就不是趁機賺一筆,而是走到技術的前沿,去推動整個生態發展。”
因此,“我們認為,中國人工智能不可能永遠是跟隨者。我們經常說中國人工智能和美國人工智能有一年、兩年的差距,但真正的差距是原創和模仿。如果這個趨勢不改變,中國永遠是跟隨者。有些探索是不可避免的。”
於是,在GPT-4發佈同年,這位未滿40的年輕人開始了他的探索。他迅速成立了一家名為DeepSeek(深度求索)的科技公司並開始招兵買馬,對於應聘者,他的要求是不求有經驗,但求有能力、热情和好奇心。因為他認為,“創新需要擺脫慣性,經驗有時會成為包袱”。在這樣的宗旨之下,這家公司迅速組建起了一支年輕且富有活力的百人團隊,里面大多都是來自清華、北大和浙大等名校的應屆生和剛畢業一兩年的青年人。
一年多後,他交出了自己的答案,也就是上文提到的DeepSeek-R1。
這一模型之所以出圈,主要是因其低成本下的高性能,据DeepSeek自己透露的数据,该款模型用時53天、不到600萬和2048張英偉達H800(较为落后)的GPU,但效果却不遜色於美國OpenAI用時半年、耗費1個億和25000塊A100 GPU所做的GPT-4,這樣的對比實在是令人心驚,也難怪引發輿論譁然。
之所以能達到這樣的效果,主要是因為DeepSeek在演算法層面進行了創新,一直以來,演算法、算力和數據被公認為是AI發展的三大支柱,而過去各大機構和公司都更多的沉浸於在算力這一方面進行“燒錢”式的屯晶片比賽,DeepSeek則另闢蹊徑,通過演算法來對大模型進行彎道超車。
美國智庫蘭德公司(Rand)研究員海姆(Lennart Heim)對此舉了一個生動的例子,早期的ChatGPT就像是讀過所有館藏的圖書館管理員,當你問問題的時候,他會根據他看過的所有書籍來回答,這個過程耗時又耗能。但DeepSeek用了另一種方法,它的管理員沒有讀過所有的書,但接受了良好的訓練,可以在被問問題時,找到正確的書來回答。
除此以外,DeepSeek還做了一件更牛的事,那就是開源,即任何人都可以自由地使用、修改、分發和商業化它的模型,這就相當於不光碼了一手好牌,還明牌了。相比之下,美國的OpenAI還是閉源模式。
DeepSeek好像真的贏麻了,中國立刻陷入了舉國般的狂歡,一批年輕的土生土長的中國應屆生打敗了科技第一國美國的頂級專家,這樣神話般的敘事充斥了中國的互聯網。
事實果真如此嗎?
DeepSeek——站在巨人的肩膀看世界
在圖靈獎得主、Meta 副總裁兼首席人工智能科學家楊立昆看來,DeepSeek的成功,與其說是“中國超越美國”,倒不如說是開源模型正在超越專有模型。
從何講起?
他表示,“DeepSeek的成功很大程度上得益於開源研究和開源社區(如Meta的PyTorch和Llama,他們是在其他人的工作基礎上提出新想法並構建的。正是因為這些工作都是公開發佈和開源的,所以每個人都能從中受益——這正是開源研究和開源精神的力量所在。”
仔細來看,DeepSeek確實在演算法上進行了一些創新,提高了模型效率,但這也是在基於前人所打造的基礎之上,而非做出了核心技術層面的突破和迭代,用比較形象的俗語來說,DeepSeek是站在了巨人的肩膀上看了世界,得益於開源。
而AI開源的鼻祖正是美國。去年7月,美國公司Meta開源了耗資上億、使用1.6萬塊英偉達H100晶片進行訓練的Llama3.1,展現出其對於開源的決心,該公司董事長紮克伯格在當日發文一篇《開源AI是前進之路》,他認為,對於世界而言,開源將確保全球更多的人能夠從AI的發展中獲得好處和機會,權力不會集中在少數幾家公司手中,技術能夠更均勻和安全地在社會中部署。
紮克伯格的願景在中國得到了實現和綻放,DeepSeek,在美國鋪好的道路上跑出了自己的加速度,如此背景下,說DeepSeek的出現意味著中國在AI領域的實力已經與美國相當,實在是值得商榷,畢竟鋪路的是別人,作為追趕者,所耗費成本自然更低,更何況,DeepSeek用的還是來自美國的晶片呢?
除此以外,DeepSeek的創新性和低成本也頗受質疑。
美國OpenAI 和白宮官員表示,DeepSeek可能通過不正當的方式利用了OpenAI的專有技術來開發其自有的AI產品 。半導體研究和諮詢公司 SemiAnalysis 也在研究報告中說,DeepSeek 的主要投資方幻方量化早在2021年美國出口管制生效前,就囤積了一萬塊英偉達先進的A100 GPU。另外DeepSeek的論文中提到的600萬美元成本僅指預訓練過程中 GPU的花費,這只是模型總成本的一部分。研發費用以及硬體本身的總體擁有成本等重要部分並未包含在內。
不過,不可否认的是DeepSeek確實打開了人們重新理解AI領域競爭的思維之門,即在開源的大背景之下,每個人、每個國家隨時都有可能異軍突起。
但這一切的基礎還是離不開算力,沒有算力,再好的算法也如空中樓閣,沒有落地的空間,正如DeepSeek創始人梁文峰自己所說:“我們面臨的挑戰從來不是錢,而是高端晶片的禁運。”
去年年底以來,美國公佈了一系列對中國AI算力供應能力全面圍堵的政策,
嚴格限制向中國出口尖端半導體。白宮在公告中表示,“我們必須確保人工智能這一關鍵技術不離岸,確保全世界的人工智能在美國的軌道上運行。”
不过据消息人士指出,DeepSeek绕开了美国英伟达的编程框架,为日后适配中国国产图形处理器做准备。DeepSeek拥有一些擅长写PTX语言的内部开发者,倘若DeepSeek未来有意改适配中国国产的GPU,在硬体适配方面将更得心应手。
不難看出,中美真正的較量現在才剛剛開始。
DeepSeek回答的中美AI发展优劣势对比
中國:
■優勢:
- 數據規模大:龐大人口和廣泛應用產生海量數據。
- 政府支持強:AI被列為國家戰略,政策扶持力度大。
- 應用場景豐富:互聯網和制造業發達,AI落地場景多。
- 人才儲備增長快:AI領域人才數量迅速增加。
■劣勢:
- 核心技術依賴:高端芯片和算法仍依賴國外。
- 創新能力不足:基礎研究相對薄弱,原創性突破較少。
- 國際環境限制:面臨技術封鎖和地緣政治壓力。
美國:
■優勢:
- 技術領先:擁有全球頂尖的AI公司和研究機構。
- 創新能力強:基礎研究深厚,原創性成果多。
- 人才吸引力大:彙聚全球頂尖AI人才。
- 資本支持充足:風險投資和資本市場活躍。
■劣勢:
- 政策連續性不足:雖然特朗普政府放開了數據監管並啟動了“星際之門”等計劃,但美國政策隨政府更迭可能出現變化,影響長期戰略的穩定性。
- 社會分歧與倫理爭議:盡管政策放寬,AI的倫理問題(如算法偏見、隱私侵犯)仍引發公眾擔憂,可能限制技術應用的廣泛推廣。
- 國際競爭加劇:中國等國家的快速崛起對美國在AI領域的主導地位構成挑戰,可能削弱其全球影響力。